はじめに
google colabを利用して検証する
- サイトから検証データ、テストデータをダウンロードし、google colabにアップロードする。
- 前処理を行うために必要なライブラリをインストールする
- 初期値を設定する
# trainデータを解凍する
!unzip train.zip
## 和暦を西暦に変換するライブラリ
!pip install jeraconv
import datetime
currentDateTime = datetime.datetime.now()
date = currentDateTime.date()
current_year = date.strftime("%Y")
- 標準でインストールされているライブラリをインポートする
## 必要なライブラリーのimport
import glob
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
データの読み込み
- 訓練データが複数のCSVファイルに分かれているので1つにDataFrameにまとめる
- データ量や欠損値データの確認を行う
files = glob.glob("train/*.csv")
data_list = []
for file in files:
# trainフォルダにあるすべてのCSVファイルをdata_frameに変換し、その値を配列に格納する
# index_col=0のようにindexとして使いたい列の列番号を0始まりで指定する。
data_list.append(pd.read_csv(file, index_col=0))
# 配列に格納したデータフレームを1つにまとめる
df = pd.concat(data_list)
# データの行数とカラム数の確認
df.shape
# 欠損値やデータ型の確認
# 0 non-nullのデータは欠損値のため、削除する
df.info()
欠損値データの削除
## 欠損値のカラムの削除
#for col in df.columns:
# if df[col].count() == 0:
# df = df.drop(col, axis=1)
nonnull_list = []
for col in df.columns:
count = df[col].count()
if count == 0:
nonnull_list.append(col)
df = df.drop(nonnull_list, axis=1)
df.info()
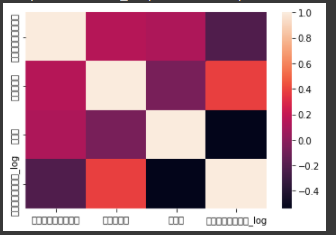
特徴量パラメータの加工
市区町村データの削除
- 市区町村名と市区町村コードは、一致するデータが入っている。
全く一致するデータが入っていることはモデルとしてよくない。
全く一致するようなデータが入っていると多重共線性が発生する。
※多重共線性とは、言ってみれば類似度の高い説明変数の間で回帰係数の「取り合い」のような現象が発生しているケースです。
# value_countsは一意の値のカウントを含むシリーズを返します。同じ結果となる場合、多重共線性が発生する可能性がたかいデータとして想定できるのでカラムを削除する
df["市区町村コード"].value_counts()
#df["市区町村名"].value_counts()
df = df.drop("市区町村名", axis=1)
種類データの削除
## describeはint型、float型のデータの統計量を返す。object型は表示されない
df.describe()
## 文字列型の統計量のデータを参照したい場合
## 文字列のデータを確認しuniqueで表示されるデータが1件の場合、すべて同じデータなので意味のなさないデータだとわかる
## そのため、種類のカラムを削除する
df.astype("str").describe()
df = df.drop("種類", axis=1)
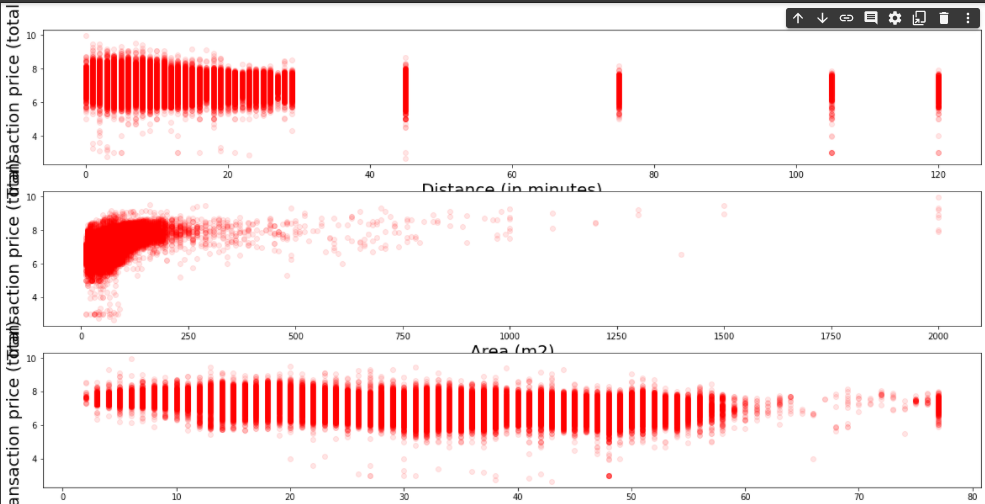
最寄駅:距離(分)データの加工
## 数字に文字列が入ってデータを加工する
pd.set_option("display.max_rows", 500)
## 分とかHなどの文字が入っていることを確認する
df["最寄駅:距離(分)"].value_counts()
## 対象の文字列を数値に変換するリストを作成する
dis = {
"30分?60分": 45,
"1H?1H30": 75,
"2H?": 120,
"1H30?2H": 105
}
## 上記のリストの内容に変換し、float型に変換して再設定する
df["最寄駅:距離(分)"] = df["最寄駅:距離(分)"].replace(dis).astype(float)
面積の加工
pd.set_option("display.max_rows", 500)
df["面積(㎡)"].value_counts()
df["面積(㎡)"] = df["面積(㎡)"].replace({"2000㎡以上": "2000"}).astype(float)
df["面積(㎡)"].value_counts()
建築年の加工
- jeraconv ライブラリを利用して和暦を西暦に変換する
- 上記で算出した値から現在の年を引くことで築年数を算出する
## 和暦のデータを西暦に変換して現在からの経過年数を格納する
from jeraconv import jeraconv
j2w = jeraconv.J2W()
#df["建築年"].valueでループすることも可能だが1行づつ全データに対して置換をしないといけないので時間がかかる
y_list = {}
for i in df["建築年"].value_counts().keys():
try:
tikunensu = int(current_year) - j2w.convert(i)
except:
## 戦前という文字列は置換できないので、固定値で
tikunensu = int(current_year) - 1945
finally:
y_list[i] = tikunensu
df["建築年"] = df["建築年"].replace(y_list)
取引時点の加工
## 取引時点
year = {
"年第1四半期": ".25",
"年第2四半期": ".5",
"年第3四半期": ".75",
"年第4四半期": ".99",
}
year_list = {}
year_replace = ""
for i in df["取引時点"].value_counts().keys():
for k, j in year.items():
if k in i:
year_replace = i.replace(k,j)
year_list[i] = year_replace
df["取引時点"] = df["取引時点"].replace(year_list).astype(float)
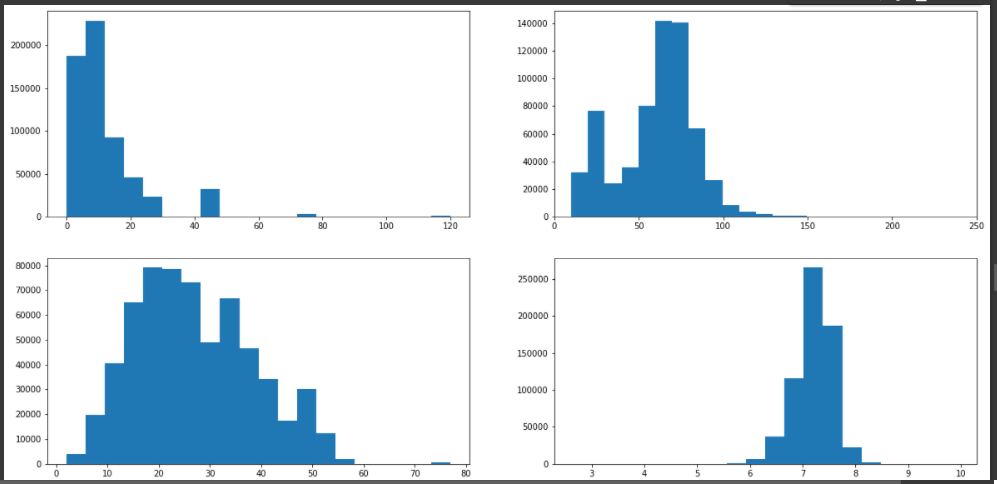
加工後のデータ
市区町村コード 最寄駅:距離(分) 面積(㎡) 建築年 建ぺい率(%) 容積率(%) 取引時点 取引価格(総額)_log
count 637351.000000 614306.000000 637351.000000 619117.000000 614848.000000 614848.000000 637351.000000 637351.000000
mean 18513.985300 11.731487 58.663570 26.978080 67.601944 301.601876 2013.633153 7.217424
std 9596.722442 12.197090 26.712019 11.496701 10.402295 148.105400 3.884546 0.353935
min 1101.000000 0.000000 10.000000 2.000000 30.000000 50.000000 2005.750000 2.653213
25% 13106.000000 5.000000 45.000000 18.000000 60.000000 200.000000 2010.500000 7.000000
50% 14104.000000 8.000000 65.000000 26.000000 60.000000 200.000000 2013.750000 7.255273
75% 27114.000000 14.000000 75.000000 35.000000 80.000000 400.000000 2016.990000 7.447158
max 47213.000000 120.000000 2000.000000 77.000000 80.000000 1300.000000 2019.990000 9.934498